Kubernetes Native Storage and a Load Balancer

As I continue to evolve my self-hosted environment to be more robust and fault-tolerant, I have completed setting up the Longhorn storage system and a bare-metal load balancer, MetalLB.
Longhorn
Longhorn provides block strorage for a Kubernetes cluster which is provisioned and managed with containers and microservices. It manages the disk devices on the nodes and creates a pool for Kubernetes persistent volumes (PVs) which are replicated and distributed across the nodes in the cluster. This means that a single node or disk failure doesn’t take down the volume and it’s accessible by other nodes. It also supports snapshots and backups to external storage such as NFS and S3 buckets.
Since I’m already using Rancher for managing my cluster, it was a straight-forward process to install as a catalog app. I created a new Rancher project called “Storage” with a namespace called “longhorn-system” in which to install it.
This process sets up the system itself incuding the storage provisioner so that persistent volume requests can be fulfilled by the longhorn storage class. In order to configure the storage itself and create volumes manually, I needed to create an ingress to the Longhorn web interface. It uses basic authentication, so following the instructions I created an auth file using:
$ USER=<USERNAME_HERE>; PASSWORD=<PASSWORD_HERE>; echo "${USER}:$(openssl passwd -stdin -apr1 <<< ${PASSWORD})" >> auth
Then create the secret from the file:
$ kubectl -n longhorn-system create secret generic basic-auth --from-file=auth
Following my previous pattern, I created an Ansible role which deploys the ingress manifest.
- name: Deploy Longhorn Ingress Manifest
kubernetes.core.k8s:
kubeconfig: "{{ kube_config }}"
context: "{{ kube_context }}"
state: present
definition: "{{ lookup('template', 'manifests/ingress.j2') }}"
validate:
fail_on_error: yes
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: longhorn-ingress
namespace: longhorn-system
annotations:
cert-manager.io/cluster-issuer: letsencrypt
# type of authentication
nginx.ingress.kubernetes.io/auth-type: basic
# prevent the controller from redirecting (308) to HTTPS
nginx.ingress.kubernetes.io/ssl-redirect: 'true'
# name of the secret that contains the user/password definitions
nginx.ingress.kubernetes.io/auth-secret: basic-auth
# message to display with an appropriate context why the authentication is required
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required '
spec:
rules:
- host: {{ longhorn_url_host }}
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: longhorn-frontend
port:
number: 80
tls:
- hosts:
- {{ longhorn_url_host }}
secretName: longhorn-ingress-cert
I was able to login in to the Longhorn UI, set up the storage pool, and manually create a volume. I wanted to test things out and investigate how I can migrate existing persistent volumes from my current provisioner (nfs-provisioner-nfs-subdir-external-provisioner) to Longhorn volumes.
The answer I found was a batch job which would mount the old and new volumes and perform a copy. I used my Valheim server persistent volume as a test.
piVersion: batch/v1
kind: Job
metadata:
namespace: games
name: volume-migration-valheim
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: valheim-server-data
- name: new-vol
persistentVolumeClaim:
claimName: valheim-test-migration
Unforunately, this did not work as expected. The container that the job was running on was not able to mount the new volume. I had noted that Longhorn said it did not support RancherOS since it’s end-of-life, but I saw some things that made think it might work if you a) switch to the Ubuntu console, b) install open-iscsi package, and c) install nfs-common package.
It does work in the sense that it’s able to provision the volume, but it doesn’t seem to be able to mount volumes across nodes via NFS in the container as it’s missing some underlying support in the OS. For those not familiar, RancherOS runs entirely as Docker containers and there are actually two Docker engines running (system-docker and userland docker) so the “OS” is actually a container as well.
Unfortunately, this effort is on hold for now. My plan is to add addtional nodes to the cluster which are standard Debian VMs running Docker using Terraform and Proxmox. The thought is to add a node, migrate workloads, then retire the old RancherOS nodes without needing to create an entirely new cluster. I’m only assuming this can be done as I described, I haven’t been able to find anyone else who has done this before and documented for me to DDG.
Load Balancer
When I was first setting up my cluster, I limited the Kubernetes Ingress NGINX controller (not to be confused with the NGINX Ingress Controller!) to run on a single node and just did a port forward to that node’s IP address in my router. The Ingress then routed the traffic to the correct node/pod inside of the cluster to respond to the request. The problem is that this introduced a single point-of-failure. This was largely mitigated by running nodes as VMs on a Proxmox cluster, but still.
Normally, a cloud provider would have a Load Balancer service which would proivide the external IP address and route traffic to the correct port and node. Kubernetes doesn’t provide this for a bare metal cluster, but MetalLB provides an elegant solution.
In my case, I have a dedicated DMZ VLAN on my home network and I was able to exclude a range of IP addresses from being given out by DHCP. This is the pool of addresses that I configured for layer 2 load balancing.
Again, following my pattern of using Ansible roles to deploy:
- name: Deploy MetalLB Namespace Manifest
kubernetes.core.k8s:
kubeconfig: "{{ kube_config }}"
context: "{{ kube_context }}"
state: present
definition: '{{ item }}'
validate:
fail_on_error: yes
with_items: '{{ lookup("url", "https://raw.githubusercontent.com/metallb/metallb/v0.10.2/manifests/namespace.yaml", split_lines=False) | from_yaml_all | list }}'
when: item is not none
- name: Deploy MetalLB Manifest
kubernetes.core.k8s:
kubeconfig: "{{ kube_config }}"
context: "{{ kube_context }}"
state: present
definition: '{{ item }}'
validate:
fail_on_error: yes
with_items: '{{ lookup("url", "https://raw.githubusercontent.com/metallb/metallb/v0.10.2/manifests/metallb.yaml", split_lines=False) | from_yaml_all | list }}'
when: item is not none
- name: Deploy MetalLB Configmap
kubernetes.core.k8s:
kubeconfig: "{{ kube_config }}"
context: "{{ kube_context }}"
state: present
definition: "{{ lookup('template', 'manifests/configmap.j2') }}"
validate:
fail_on_error: yes
The namespace.yaml and metallb.yaml manifests come directly from the MetalLB Github repo so I only needed to create a configmap specific to my environment:
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.x.2-192.168.x.5
The last step was to create a Load Balancer for the Ingress controller (converting from NodePort configuration):
apiVersion: v1
kind: Service
spec:
clusterIP: 10.43.x.x
clusterIPs:
- 10.43.x.x
externalTrafficPolicy: Local
healthCheckNodePort: 31431
loadBalancerIP: 192.168.x.5
ports:
- name: "80"
nodePort: 30176
port: 80
protocol: TCP
targetPort: 80
- name: "443"
nodePort: 32182
port: 443
protocol: TCP
targetPort: 443
selector:
workloadID_ingress-nginx: "true"
sessionAffinity: None
type: LoadBalancer
One important bit is that the externalTrafficPolicy is set to local which preserves the source IP of the request. Otherwise, it would show the IP of the node which originally received the request. Another important bit is that I’m requesting a specific IP address from the pool for the Load Balancer so that I can port forward to that IP in my router. Otherwise, it would just assign the next available IP address in the pool.
So, what is going on here?
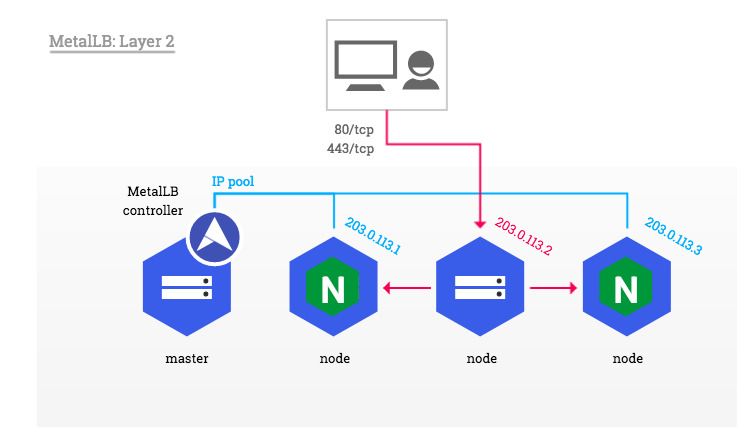
One of the nodes in the cluster will advertise itself as the load balancer IP address and will distribute the requests to the ingress controller on the same node. If that nodes goes down, another node will pick up the slack and start advertising itself instead. So layer 2 is not really load balancing, but merely a failover and there can be a delay before the new node starts sending out the ARPs. In any case, I can get traffic into the cluster and it’s nice to have another layer of redundancy.